Using Ansible to restore developer sanity
July 2015
This time a year ago we were deploying new code to Oyster.com using a completely custom deployment system written in C++. And I don’t mean real C++; it was more like C with classes, where the original developers decided that std::string was “not fast enough” and wrote their own string class struct:
struct SIZED_STRING
{
const uint8_t *pbData;
size_t cbData;
};
It’s not our idea of fun to worry about buffer sizes and string lengths when writing high-level deployment scripts.
Then there was the NIH distributed file transfer system — client and server. And our own diffing library, just for fun. All very worthwhile things for a hotel review website to spend time developing in-house! :-)
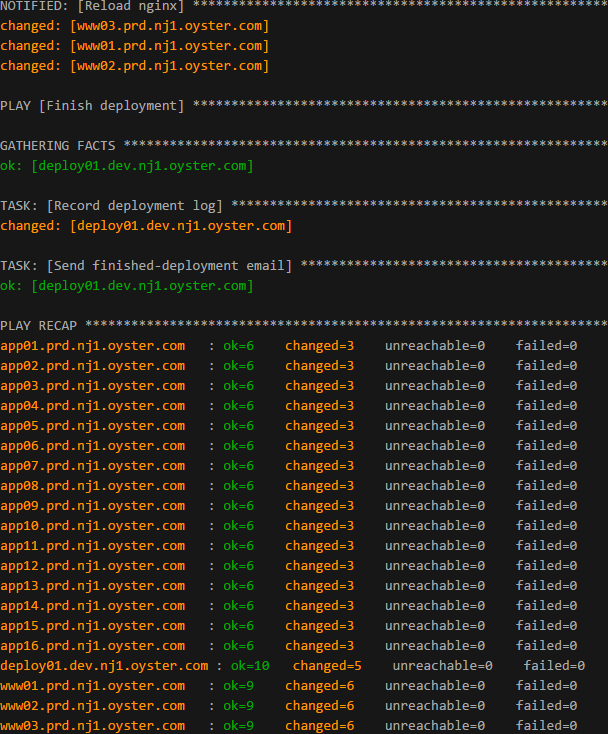
Sarcasm aside, this wasn’t a joke: we replaced more than 20,000 lines of C++ code with about 1000 lines of straight-forward Ansible scripts. And it really did restore our sanity:
- Rather than 28 manual steps (some of which, if you ran out of order, could bring the site down) we run a single Ansible command. All we have to specify manually is which revision to deploy and type in some deployment notes to record to our internal log (for example, “Shipped mobile version of hotel page”).
- Instead of spending hours digging into log files on a remote machine whenever our fragile home-grown system broke, Ansible gives us clear and generally easy-to-track down error messages. The most we have to do is SSH to a machine and manually restart something.
Choice of tools
Some teams within TripAdvisor use Chef for server setup (and other tools like Fabric for code deployments). We also looked briefly at Puppet. However, both Chef and Puppet gave us a very “enterprisey” feel, which isn’t a great match for our team’s culture.
This is partly due to their agent-based model: Chef, for example, requires a Chef server in between the runner and the nodes, and requires you to install clients (“agents”) on each of the nodes you want to control. I think this picture gives a pretty good idea of the number of components involved:
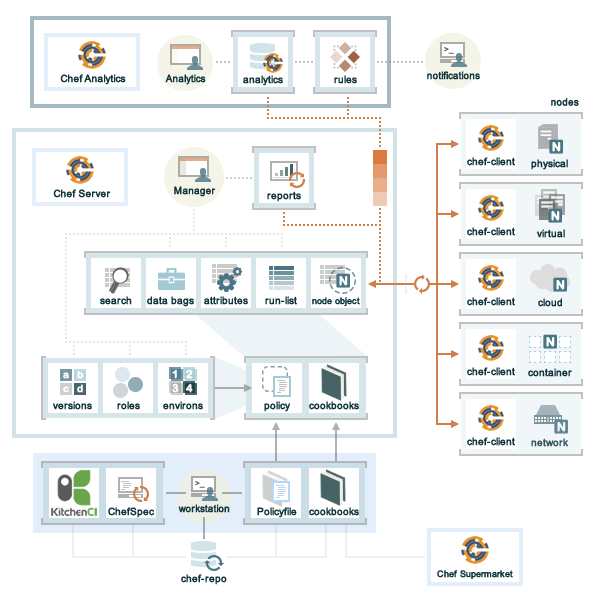
In contrast, Ansible has basically five parts:
- playbooks
- inventory files
- vars files
- the
ansible-playbookcommand - nodes
I’m sure there are advantages and more power available to systems like Chef, but we really appreciated the simplicity of the Ansible model. Two things especially wooed us:
- You don’t have to install and maintain clients on each of the nodes. On the nodes, Ansible only requires plain old SSH and Python 2.4+, which are already installed on basically every Linux system under the sun. This also means developers don’t have to learn a new type of authentication: ordinary SSH keys or passwords work great.
- Simple order of execution. Ansible playbooks and plays run from top to bottom, just like a script. The only exception to this is “handlers”, which run at the end of a play if something has changed (for example, to reload the web server config).
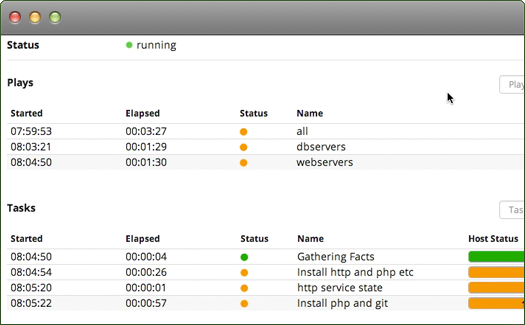
Ansible Tower UI
Ansible itself is free and open source and available on GitHub. But they also provide a fancy web UI to drive it, called Ansible Tower. It’s nice and has good logging and very fine-grained permissions control, but we found it was somewhat tricky to install in our environment, and as developers it didn’t gain us much over running a simple command.
Our thinking is that in a larger organization, where they need finer-grained permissions or logging, or where non-developers need to kick off deployments, using Ansible Tower would pay off.
Our deployment scripts
As noted above, Ansible has a very simple order of execution, and its model is kind of a cross between declarative (“get my system configuration into this state”) and imperative (“do this, run this, then try this”). Our site deployment involves some system configuration, but is mostly a series of steps that “orchestrate” the deployment. Here’s more or less how it works:
- Setup: update code, run tests on staging server, upload new static assets.
- Turn off B app servers, run on A (we have 8 Python app servers in each group).
- Update code on B app servers.
- Turn off A app servers, run on B (making new code live on B).
- Update code on A app servers.
- Make all A and B app servers live.
- Record deployment log and send “finished deployment” email.
To show you some example Ansible code, step 3 (and step 5) use the following code:
---
- name: Update code on B app servers
hosts: app_b
tasks:
- name: Update code on app servers
subversion: repo={{ svn_repo }} dest={{ code_dir }} username={{ svn_username }}
password={{ svn_password }} revision={{ svn_revision }}
- name: Restart app service
service: name=server-main state=restarted
- name: Wait for app server to start
wait_for: port={{ app_port }} timeout=300
- name: Check that new version is running
local_action: uri url=http://{{ inventory_hostname }}:{{ app_port }}{{ version_url }}
return_content=true
register: response
failed_when: response.json['SvnRevision'] != {{ svn_revision }}
As you can see, Ansible uses fairly straight-forward YAML syntax. In the above code, Ansible runs these tasks against our 8 “app_b” hosts in parallel — a simple but powerful concept.
For a given “play” such as the above, each task is executed in order — we really appreciated how it doesn’t try to outsmart you in terms of how and when things run. The only exception to this is Ansible’s handlers, which are tasks run at the end of a play, but only if something “notified” them. For example, in our deployment, handlers are used to restart our nginx servers when the nginx config file changes.
You’ll see there are a lot of {{ variables }} used here: each task line is actually a Jinja2 template string that is rendered against your current set of host variables. This makes it very easy to modify settings which change depending on environment (staging, production, etc). It also separates playbooks from user-specific data, meaning settings aren’t hard-coded in playbooks and folks can share them much more easily.
We deploy solely to Linux-based machines (about 50 nodes), and Linux is where Ansible started and where it excels. However, we have something of a Windows history, so it was interesting to learn that as of August 2014 (version 1.7), they started adding support for managing Windows machines — this is done via Powershell remoting rather than SSH.
In short, what sold Ansible to us was:
- Simple YAML-based syntax
- Simple execution order: top to bottom, and then handlers
- Powerful: Jinja2 templates, large library of builtin modules
- Agentless: no client to install and maintain
Pre-Ansible, we dreaded our 28-manual-step deployments. Post-Ansible, it’s almost fun to deploy code, and the focus is on the features we’re deploying, instead of “what’s going to go wrong this time?”. So I hope you get the chance to try Ansible! And no, we weren’t paid to link that…